Hi everyone!
Here comes a not so spectacular, but hopefully funny update for I Am Overburdened. As the name suggest version 1.2.5. is way more swift than the previous one, plus it is equipped with a nasty new trick to terrorize artifact hunters ;)
Hallucination 2.0
Please welcome "positive" hallucinations. Previously when you accidentally drank poison or a venomous creature attacked you, monster phantasms (non-existent hallucinated creatures) would be placed randomly on the following dungeon level.

This feature always felt fun, but a bit insignificant. Its impact was quite low because if you played a lot you could figure out in many cases which of the monsters are hallucinated and you never feared extra monsters when in a good shape (health and loot wise).
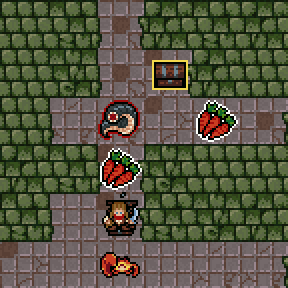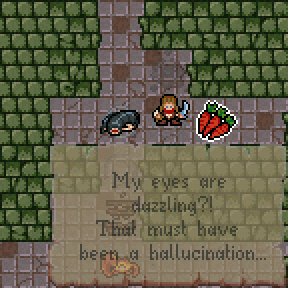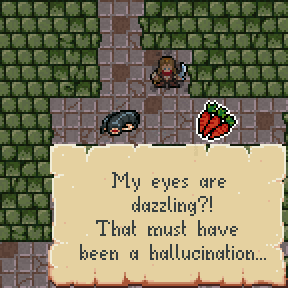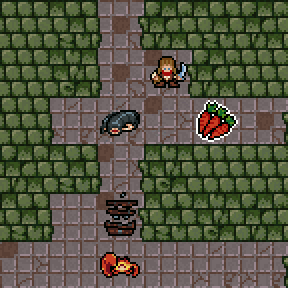
Now other entities (chests, pickup, etc...) can be hallucinated and their placements are influenced by the level templates and the dungeon generator. The new version is way more effective, a.k.a. confusing :D
If you have an existing save-game no worries. The new save files may be a tiny bit bigger (due to the more complex hallucinations), but the game is backward compatible.
Inventory triviality
A tiny ease of use feature. Now when opening your inventory while standing next to an item or opened chest the relevant item slot will be focused. The slot of the last picked up item still has priority though!
Optimization
I keep saying that I Am Overburdened runs on a toaster, but what does this mean and is it really true? Well, for the most part, it IS true. I have a 10+ years old laptop on which I test the game from time to time (1st gen 1.5Ghz Atom CPU, 1Gb RAM :O for real) and the game is able to run at 60 fps (not that it matters a lot with a turn-based game :D but still). My work desktop is also quite modest so a performance mistake surfaces easily. The more taxing parts where the real problems lie are switching between screens and launching the game.
Checking loot
Sadly the inventory screen had a blatantly unoptimized implementation. Opening it could cause almost a second long halt on my older machine. It was still my original prototype implementation. Silly me, sorry for the inconvenience. I simplified the layout data of the screen, remade the loading algorithm and voila. Now it can load within the same frame of the press/click even on a simple computer.
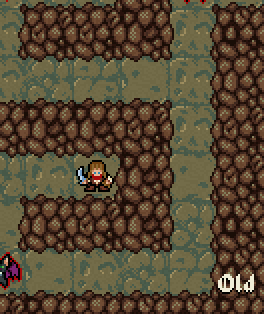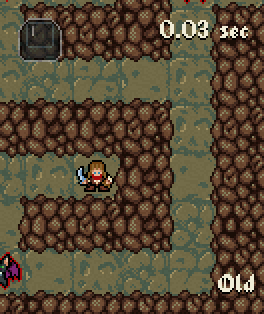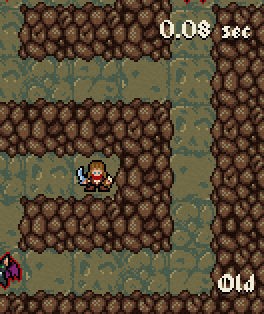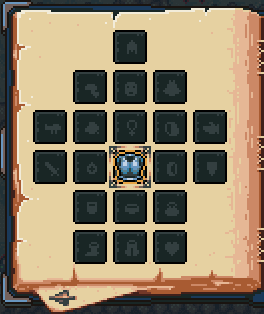
A bit slowed down recording of opening the inventory in the old and the new version for comparison.
Parts of these changes got into the previous version so you may have experienced the speedup to an extent already.
Startup

So on the before mentioned toaster, it took 5+ seconds to show the title screen after launching the game. This was mainly due to pre-loading almost all the assets and saved data so that handling the content while the game is running can be simple. I postponed tiny parts of this, but the logic largely stayed the same and instead I choose to simplify the majority of the game data to speed-up load times. Still not lightning fast, but I measured a hefty 40-50% win which is really nice :)
Tech talk
So doing some optimizations is definitely a nice thing for the game, but the readers probably won't die from excitement after skimming through these paragraphs :D
To spice up the entry a little I'm going into some of the details. Warning, technobabble ahead!
Starting out optimizing?
Easy: measure, measure and measure. Don't dive in changing around stuff like a madman since you could easily try to optimize algorithms which don't really take much time or you could introduce massive changes without big wins. Once you have the answer to "what specifically needs to be optimized" and "what can actually be optimized (preferably with the least effort)" questions you are officially ready to make a mess out of those parts of your code-base ;)
After you change something guess what? You measure some more to make sure your experiments do make things faster...
Skeletons in the closet
I mentioned a lot of data and loading related changes. Simply because reading meta-data took the most time (descriptions of items/monsters/pickups/chests/skills/effects + screen layouts and settings). I knew instantly I could easily optimize these with big wins, because I'm a lazy programmer :) What that means is I often use simple, generalized tools (usually built-in or third-party and throwaway solutions) for many things to save development time, but these tend to be quite slow (like XML and reflection...).
var monsterDescriptions = xmlSerializer.Deserialize<MonsterDescription[]>(file);Yes, it really is this simple to load stuff if you are lazy ;)
Before someone attacks me for my choice, I'm not advocating this approach. It does usually work out, but I know that these shortcuts can bite you later on.
Back to optimizing
So switching to a format which is easier to parse and still not hard to work with. My solution: CSV
It eliminates redundant data, tooling support is quite good (excel, google docs, etc...), it is still text-based and super-duper simple to load.
<!-- ... -->
<EffectDescription>
<Name>Splash</Name>
<Sprite>EffectSplash</Sprite>
<EaseInSeconds>0.35</EaseInSeconds>
<EaseOutSeconds>1.0</EaseOutSeconds>
<MaxTransparency>0.66</MaxTransparency>
<AllowFlip>false</AllowFlip>
<Layer>Ground</Layer>
</EffectDescription>
<!-- ... -->The old XML version of a special effect for a skill.
Name,EaseInSeconds,EaseOutSeconds,Sprite,MaxTransparency,AllowFlip,Chained,Layer
...
Splash,0.35,1,EffectSplash,0.66,False,,Ground
...The CSV version of the same effect (the header/meta-info is not repeated for each entry as opposed to XML).
My first tests showed a whopping 75-80% load time decrease with some types so I went full steam ahead with converting the data and the loading routines to CSV.
I know there are actual wars fought over XML versus JSON versus YAML versus INI/TOML etc... with a lot of casualties already :D , but before I get some glaring looks for my idiotism for originally using XML over JSON as an example think again! With JSON/YAML/... you still have a ton of redundant data (the property names are duplicated for each object the same way as with XML) and you are probably still using reflection (which is a huge factor in speed) whereas with manual loading and a simple format like CSV you do get 0 redundancy and can easily implement parsing without any runtime type information.
EffectDescription ReadEffectDescription(CSVLineReader lineReader)
{
// each Read* call jumps to the next cell in the CSV line
var effectDescription = new EffectDescription();
effectDescription.Name = lineReader.ReadString();
effectDescription.EaseInSeconds = lineReader.ReadSingle();
effectDescription.EaseOutSeconds = lineReader.ReadSingle();
effectDescription.Sprite = lineReader.ReadString();
effectDescription.MaxTransparency = lineReader.ReadSingle(effectDescription.MaxTransparency);
effectDescription.AllowFlip = lineReader.ReadBoolean(effectDescription.AllowFlip);
var chained = lineReader.ReadString();
if (!string.IsNullOrWhiteSpace(chained))
{
effectDescription.Chained = chained;
}
effectDescription.Layer = lineReader.ReadEnum<EffectLayer>(EffectLayer.Spell);
return effectDescription;
}Reading the effect shown before using a simple manual (non-reflective) CSV reader construct.
With converting a huge chunk of the data I saved some disk space too. From 62727 (XML) to 11930 (CSV) bytes which is almost an 81% reduction in size :O
Tips time!
Spidi, this all sounds nice but what if I have complex composite data (vectors, colors, arrays) or nested data (dictionaries, trees). Most of these problems can be addressed:
- Vectors/colors turn into multiple columns (position.x, position.y, colortint.r, colortint.g etc...), or you can turn them into single-cell string "scalar" value: 123;456 (x;y ';' character used as separator), 0xFF0000FF (color red as hex RGBA) etc...
- Arrays/lists are a bit trickier, but if you have relatively small collections (only a few entries) you can use the same approach as with vectors: 0;1;2;3 (';' character used as the entry separator).
- Dictionaries? No problem! The first column can be a "Key" column if it can be expressed as a scalar. Done.
- Trees with parent and child relations? No problem! The first column can be the "Id" column to identify elements and the second is the "Parent" which has the id of the parent element. This way you just need to look out for ordering or you build the tree as a "post-load" step.
If all else fails?
Then you either stick to your exiting format if optimizing it is not an absolute must or you look for a different representation (e.g.: binary) if it has to be faster. To give an example for both cases the save-games in I Am Overburdened had a hand-rolled binary format from the get-go, but I "had to" stick to XML for the item database.
In the latter case, I did not want to lose the ease of editing of items (a lot of work goes into tweaking them) plus the skill data structure is super complicated. I did manage to throw out reflection and use a hand-rolled parsing method though...
Oh my goodness, but parsing XML/JSON/YAML/... by hand is utterly disgusting isn't it? Well, there are patterns to make it pretty simple:
// XmlPacker structure, PackUnpack methods implementing read & write for each primitive
string PackUnpack(string name, string value)
{
if (this.IsReading)
{
// Checks whether a property read has to be performed
// and if the name matches the node
if (ShouldRead(name))
{
return this.Reader.ReadElementContentAsString();
}
}
else if (this.IsWriting)
{
this.Writer.WriteStartElement(name);
this.Writer.WriteValue(value);
this.Writer.WriteEndElement();
}
return value;
}
// Item class
void PackUnpackPropertiesXml(ref XmlPacker packer)
{
this.Name = packer.PackUnpack("Name", this.Name);
this.Type = packer.PackUnpackEnum("Type", this.Type);
this.Sprite = packer.PackUnpack("Sprite", this.Sprite);
this.Sound = packer.PackUnpack("Sound", this.Sound);
this.Level = packer.PackUnpack("Level", this.Level);
// other properties ...
}
// When reading "PackUnpackPropertiesXml" is run in a loop for all child nodesThis is called the pup or pack-unpack pattern (at least that is how I know it) and it helps immensely. The actual property parsing code becomes really simple and you will get both a reader and a writer method automatically only by making this one method for a type.
Validation
Yep, these are relatively major changes for extra performance so besides measuring your results you should definitely evaluate whether the data loaded from the new format matches exactly the old version!
Some tips on how to do this efficiently if you have the old loading methods and the new one is already implemented:
- Equals: implement an equality check for the given type and evaluate with it whether the data loaded from the old format matches the data loaded from the new format.
- Write: implement a write (save) method for the given type in an arbitrary expansive format and save both the data loaded from the old format and the data loaded from the new format. Now compare the saved data.
- Assert: generate a bunch of unit tests from the original data. You can execute these asserts on the data loaded from the old format (to make sure code generation worked as intended) and then on the data loaded from the new format. This is my favorite by the way.
Was it all worth it for faster startup and inventory opening? Yes, absolutely! Besides improving the user experience, I always had plans of porting the game to mobile platforms. In the last few months with all the optimizations I've done I believe it is going run flawlessly without sucking the batteries dry ;)
Upcoming?
My hand is only a tiny bit better, but at least it is not killing me nowadays. I'm slowly and carefully working towards finishing the expansion for I Am Overburdened. Sorry for not sharing new details about it with this entry. To make up for it I'm going to post images and gifs showcasing some of the new monsters and items with the following update ;) For next time I'm planning to release another tiny graphical enhancement.
Thanks for reading my post and much love for your support.
Stay tuned!

