The Problem
Despite what certain people want you to think these days, virtually every game profits from good performance and high frame rates. This is especially true for fast games that test the player's reflexes, like Roche Fusion.In fact Roche Fusion's performance has never been bad. It runs at 60+ FPS on virtually anything one would buy today, and especially machines with newer graphics cards can easily reach up to 200 or 300 FPS, even in full HD.However, those numbers can be deceiving, since they apply to the menu (where an AI plays a simple game in the background) or the beginning of a new round. In those situations, the performance is completely dominated by the fill-rate limits of the graphics card, chewing through millions of pixels for post processing each frame. Some minutes into a typical game however, this changes. The reason for this is explosions. Lots of explosions.

Figure 1 - explosions

Figure 2 - "lots of explosions"
Not surprisingly, profiling shows that about 95% of all our CPU time is used simulating and drawing particles. On an even closer look it becomes clear that the major culprit are the particles that are created from the sprites of exploding ships.
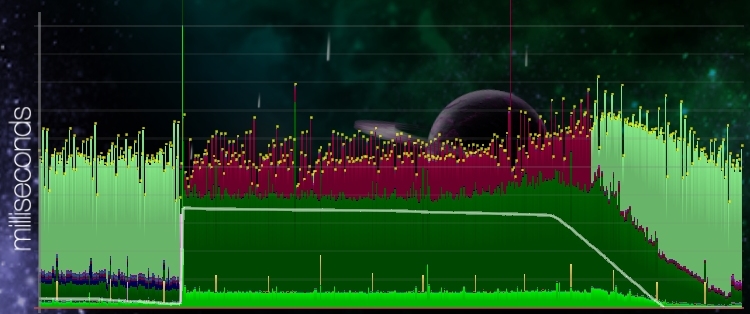
Figure 3 - performance before changes
Figure 3 shows a screenshot of Roche Fusion's performance graph taken just after the explosion of a player ship, which spawns roughly 4000 particles. Note that before and after the explosion, the game is clearly fill-rate bound (light green). During the explosion, even though the frame time does not noticeably increase (total height of the graph), the game is now also bound on the CPU. The medium green at the bottom of the graph represents the update time of the game, which is significantly increased during the explosion. The dark green and red bars represent the time to fill the vertex- and indexbuffers with the data needed to draw the particles, and to copy those buffers into GPU memory. The additional slight bump towards the end of the explosion is caused by a separate particle effect simulating an expanding shockwave. We will focus on the first effect however, since that is where most of our time is lost.
Analysis
Before one tackles a problem like this, it always helps to first analyse it, to make sure all probably causes are known and covered. Here, both theoretical and practical experience, as well as profiling tools come in handy. Ignoring possible micro-optimisations, which should generally only be attempted as a last resort, the four major possible sources of the phenomenon are the following.1. Each particle is represented by an object on the managed heap, and in a linked list for easy removal. While the complexity of this is optimal, it might still cause a huge amount of overhead that would not be necessary if the particles were for example stored in a simple array. This would not only allow for more compact storage, but it would also make it possible to extract common information of the particles by grouping them appropriately.2. Each particle behaves in a completely parametric way. That means that it does not interact with any unpredictable elements on the game, and instead of moving it forwards a little bit each frame, we could simply calculate the correct position when drawing the particle, based on the time it has been alive. In fact, the type of particle we are looking at behaves completely linearly, which makes calculating its position and rotation almost trivial. However, even more complicated behaviour can be so treated, as long as it is completely parametric.3. We create and upload the entire particle to the graphics card every single frame, even though most of its information does not change. This is a huge waste of CPU time, considering that we mostly copy the same data back and forth every single frame.4. For each particle, we upload four vertices (the corners) and six indices (to form two triangles) to the GPU. While this is easy and fully functional, it again introduces redundancy, since the vertices share information and the indices are so regular they could in principle be inferred.
Solution
There are a number of ways of dealing with almost any combination of these problems, some of which already mentioned above. Among them there is a way to solve all four issues at the same time. While somewhat technically complicated, this seems like the best chance of solving the problem and improving performance.The solution in question is simulating the particles entirely on the GPU. As we will see below, using the geometry shader stage introduced in DX10 and OpenGL3.2 will play an integral part in making this process efficient. The general idea is as follows.
- On an explosion, we create a vertex-buffer containing one vertex per particle and upload it to the GPU.
- Each frame, we render that vertex-buffer using a shader with the following stages:
- Vertex Shader: Move and rotate the particle to where it has to be this frame using its parametric properties.
- Geometry Shader: Generate a triangle-strip with four vertices for each particle, expanding the vertices from the center of the particles to its corners, based on the rotation and size of the particle.
- Fragment Shader: Render the particle, exactly like we did before.
- Once all particles have faded out (the maximum lifetime is know beforehand), we simply release the vertex-buffer and stop rendering it.
As is immediately clear, this approach, if successful solves all the four problems mentioned above. We do not keep the particles in a linked list, in fact we do not keep them in CPU memory at all, but only on the GPU. Further, we do not update them needlessly, but only move them to the correct position each frame. We also neither store nor upload more data than is needed, generating the actual sprites from points in the geometry shader on the fly.The implementation of this is pipeline is not trivial, and requires a considerable amount of code, so we can not look at all of it here. However, here are some simplified excerpts from the vertex and geometry shader, to show the general concepts.
Vertex ShaderCode: Select all
uniform float time;in vec3 v_position;
in vec3 v_velocity;
in float v_deathTime;
in float v_angle;
in float v_angleVelocity;
in vec2 v_size;out Vertex
{
vec3 position;
float angle;
float deathTime;
vec2 size;
} vertex_out;void main()
{
// move and rotate particle
vertex_out.position = v_position + v_velocity * time;
vertex_out.angle = v_angle + v_angleVelocity * time; // pass through time of death and size
vertex_out.deathTime = v_deathTime;
vertex_out.size = v_size;
}
Geometry ShaderCode: Select all
layout (points) in;
layout (triangle_strip, max_vertices = 4) out;uniform mat4 transformationMatrix;uniform float time;in Vertex
{
vec3 position;
float deathTime;
float angle;
vec2 size;
} vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/];out Fragment
{
float alpha;
} vertex_out;void main()
{
// discard already faded particles
if(vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].deathTime <= time)
return; // simple particle alpha
vertex_out.alpha = time / vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].deathTime; // build rotated coordinate frame
float angleSin = sin(vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].angle);
float angleCos = cos(vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].angle);
mat2 rotation = mat2(angleCos, angleSin, -angleSin, angleCos); vec3 uX = vec3(rotation * vec2(1, 0), 0);
vec3 uY = vec3(rotation * vec2(0, 1), 0); uX *= vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].size.x;
uY *= vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].size.y; // emit vertices
vec3 p = vertex_in[img]http://rochefusion.com/assets/img/news/devlog-gpu-particles/0].position + uX + uY;
gl_Position = transformationMatrix * vec4(p, 1.0);
EmitVertex(); /* three more vertices */ // end triangle strip to form quad
EndPrimitive();}
Results
While the method described above required a moderate rewrite of the central particle system of Roche Fusion, the results are so convincing, that it is pointless to show a screenshot. The game looks exactly like it did before. Yet looking at the resulting performance display reveals a stunning difference.
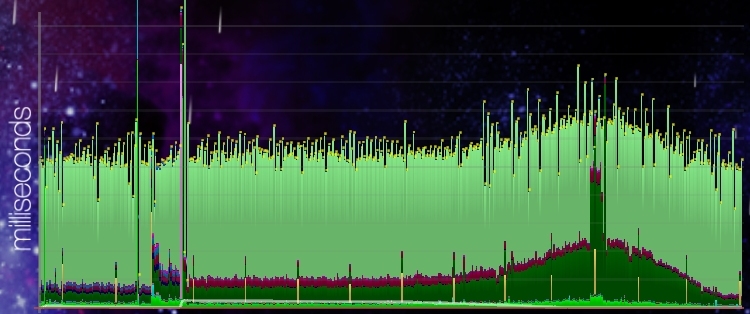
Figure 4 - performance after changes
Figure 4 shows the exact same game event as figure 3 did before the changes. This time there is hardly any difference between before and during the explosion, apart from the slight bump caused by the shockwave effect.Suffice it to say, this is the ideal outcome of the experiment, and the new code has already been shipped in the latest closed beta build of Roche Fusion, and seems to be running perfectly on a variety of configurations.Looking to the future, this does not only allow us to include even more explosions in the game, but it also enables us to use the freed up CPU time to make the simulation of the actual game more complicated, by adding all sorts of interested behaviours, without the fears of contributing to an existing problem.Further, we will move several others of our most used particle effects to be at least partly simulated on the GPU to improve performance even further.As a last treat, here is a screenshot of one of the game's ultimate weapons being fired, and the respective performance graph. After the changes made, there only is a single spike in performance, caused by dozens of enemies exploding virtually at the same time, resulting in tens of thousands of particles being uploaded to the GPU in rapid succession. While this breaks the 60 FPS barrier for a few frames, it would previously have looked like three or four of the graph in figure 3, stacked on top of each other.

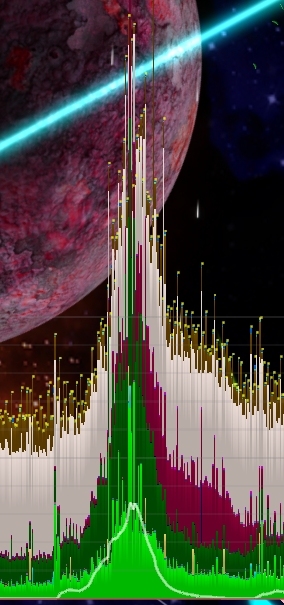
Please comment if you would like to know more about any aspect, or if anything is unclear, and let me know if this was helpful to you.For now, enjoy the pixels! (and the particles)
