In order to provide players with endless game-play in Trudy's Mechanicals we chose to procedurally generate maps. However this poses the problem that we can not pre-bake any of the lighting off-line. In order to get the best graphics as possible in Trudy, we chose to generate our lighting on the fly and it had to be as fast as possible. Luckily these kinds of calculations are easily parallelised using the iPhone 3GS/4 and iPad's NEON unit!
The Architecture
For the sake of this article I'm going to be assume that you have some grasp of the ARM architecture and assembly programming in general. NEON is a super-set of the existing VFP floating point units found in older iDevices and features sixteen 128bit quad-word SIMD registers.
Each 128bit register can be thought of as two 64-bit registers or four 32-bit registers. These registers are named as follows:
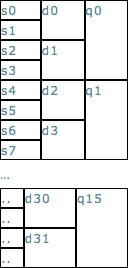
NEON instructions operate on "qX" and "dX" registers. VFP instructions operate on the first 16 "dX" and the first 32 "sX" registers. For more information see the official ARM docs.
Configuring your project in XCode
Any assembly you write will only work on your iDevice because the Apple chose to create a simulator instead of an emulator for debugging code on your Mac. Including "TargetConditionals.h" imports several defines that allow us to figure out what sort of compilation is occurring. The most important is TARGET_IPHONE_SIMULATOR which is set when compiling for the simulator.
#if TARGET_IPHONE_SIMULATOR
// put your non-optimized C/Objective-C code here
// put your assembly here
XCode itself is geared towards creating binaries for all iPhone/iPad devices. In order to compile for the iPhone 3GS/4 or iPad we must change some build settings:
1) Un-check "Compile for Thumb"
![]()
2) Set "Valid Architectures" to "armv7" (Yes this doesn't say Cortex-A8 but its fine) and check "Build Active Architecture Only".

3) Under the Build drop-down un-check armv6 if it is.

An Example
Most of the time the compiler will do a much better job creating assembly code than you, however transposing a 4 dimensional matrix is a great use case for switching to assembly. Traditionally you'd be forced to interchange the various elements of a matrix with several swaps. Using the NEON unit we can load the entire matrix into memory and using some trickery swap the elements and write them back.
void mat4_transpose(float mat[4][4])
{
#if TARGET_IPHONE_SIMULATOR
float tmp;
tmp = mat[1][0];
mat[1][0] = mat[0][1];
mat[0][1] = tmp;
tmp = mat[2][0];
mat[2][0] = mat[0][2];
mat[0][2] = tmp;
tmp = mat[2][1];
mat[2][1] = mat[1][2];
mat[1][2] = tmp;
tmp = mat[3][0];
mat[3][0] = mat[0][3];
mat[0][3] = tmp;
tmp = mat[3][1];
mat[3][1] = mat[1][3];
mat[1][3] = tmp;
tmp = mat[3][2];
mat[3][2] = mat[2][3]
mat[2][3] = tmp;
__asm__ volatile (
// load the matrix into q0,q1,q2,q3
"vldmia %0, {d0,d1,d2,d3,d4,d5,d6,d7} \n\t"
Thumbs up man. This was a well defined explanation. Thanks!