The way it was
The AI for the blobs and the humans (entities) was one giant finite state machine. If an entity was told to attack, it first had to walk to the target. As it was walking, it had to make sure it was close enough. How close it needed to be depended on what weapon or method of attack it was going to use. What weapon it was going to use depended on several other states. If it was walking, it could also be walking to a location to stand guard, or to pick up an item. Suddenly this 'walk' state had to know about all other actions that it might be preceding. If I wanted the entity to be able to do something else after walking, I had to add it in there and make sure it didn't jump into any of the other states. In the code this made for many, many, if-else statements. Chaining actions became difficult to maintain. And sharing this code between different kinds of entities who are supposed to act differently became a nightmare to manage.
Welcome GOAP
After many frustrated nights and realizing that this AI wasn't doing anything for me (I had to tell it to handle every possible state and hold its hand in case it fell), I got fed up and did some research. I heard about Goal Oriented Action Planning and decided to give it a try. In a nutshell it works like this:
Goal Oriented - you have a desired goal state you want to reach, such as "attack entity 123"
Action - Entities can perform actions, such as animations or causing damage
Planning - Plan out the best way to reach the goal using the entity's actions
Actions:
Entities have 'Actions'
Actions have 'preconditions'
Actions also have 'effects'
Chain together a list of actions that will fulfill some desired goal state.
Some example actions are: move-to, attack, pick-up, look-at
In order for an action to run there needs to be some preconditions set or else any action could run any time or they could run when they really shouldn't. You cannot punch something if you are out of range!
An as example, the Attack action is given the precondition "inRange".
So how do we know what actions are needed to place the entity "inRange"? This is where the 'effects' come in. When an action runs it updates the local state of the entity. In this case we set the move-to action to have an effect of "inRange". Chaining the actions together we get: moveTo -> attack
The change in state looks like this:
'not in range' -> (perform moveTo action) -> 'in range' -> (perform attack action) -> 'enemy is dead'
By bringing in the preconditions and effects onto the actions themselves, they do not need to know what the other actions have. And it the code this makes it much easier to look at and maintain. The MoveTo action doesn't need to know that it might be going to attack next, it doesn't care. It just needs to know a location to move to.
This now becomes really easy to add more actions into the mix. Say if you had a weapon and in order for it to fire it needed to have ammo, and in order to reload it, it needed to be drawn. This is how those actions would look:
Action Preconditions Effects
---------------------------------------------------------------------
Attack inRange,hasAmmo attackEnemy
MoveTo inRange
DrawWeapon weaponDrawn
Reload weaponDrawn hasAmmo
Chaining these together gives us:
MoveTo->DrawWeapon->Reload->Attack or DrawWeapon->Reload->MoveTo->Attack or even DrawWeapon->MoveTo->Reload->Attack
All of this is pieced together by the GOAP Planner with the preconditions and effects of each action.
If we wanted to add in a new action for a different kind of entity, say "teleport", we could just add that action to the list, give it an "inRange" effect, and then it can be used automatically without having to change any other effects. Neato!
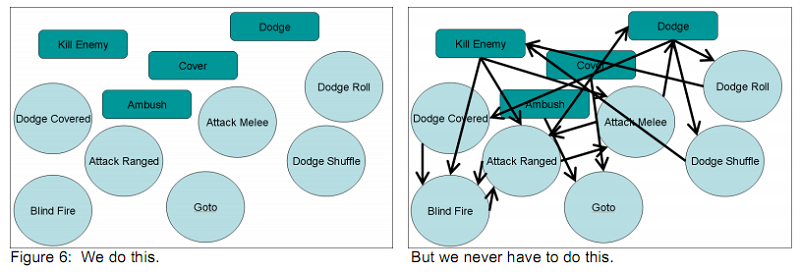
[image from Web.media.mit.edu]
As you can see in the diagram, having all of the actions separated from each other is much easier to maintain conceptually and in-code. Get rid of those nasty nested if-else statements.
In Practice
It's all well and good talking about these actions abstractly, that's easy. But what does an action actually look like? Well, often an action is just an animation. For example if a blob has nothing to do it will sometimes be given the order goal to "look busy", and the action to fulfill that goal will be the LookAround action that has the effect "look busy". This action just plays an animation and lasts for a few seconds.
Several actions are only useful if they have a target or an actual location. To help with this all preconditions and effects are a "key":"value" pair.
The Reload action's effect is a simple boolean: "hasAmmo":true
The MoveTo action has an effect that is a 3d location: "inRange":(0.1,3.5,7.2)
The Attack action has an effect that is an entity's ID: "attackEnemy":enemyId78345
Finding the best action
Deciding what actions to use begins with the Goal State that you give the entity. If an entity is not given an "attackEnemy" goal state, then it isn't going to run the Attack action. If it is just given an "inRange" goal state, then it will end up just using the MoveTo action, since the other actions do not help to get to that goal state. If I really want to force an entity to reload its weapon (say it has a cool looking animation) then I can add "attackEnemy" and "hasAmmo" to the goal state, even if the entity already has ammo from reloading last attack.
With all of these actions (their preconditions and effects) and a goal state, we now need to find what actions would be the best to reach that goal, especially if several actions can take us there. To help with this, every action is given a cost. Performing 4 actions each with a cost of 1 each will be cheaper than performing 2 tasks whose cost adds up to 9.
These costs change dynamically based on various events throughout the game. For example if a civilian is scared, their Run action might be cheaper than their Walk action; even though normally they would just walk places. Repeatedly performing an action can also increase its costs just so that other, more expensive, actions can have a chance at running and it won't look so repetitive.
To find the best path, a graph is first built up of all the actions chained to other actions (only if their preconditions match the effects of the previously performed actions. With this branching tree of actions built, it is easy to check the distance (cost) down to the end of each branch. The cheapest branch is the one we will use.
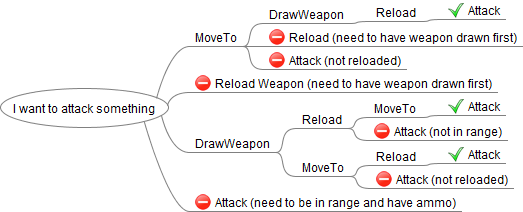
After that the entity is given a list of Actions to perform, and away it goes!
In Conclusion
Maintaining a large finite state machine graph of actions linking to each other was messy. GOAP removes these lines between each action and fills them in automatically for you. It also allows you to easily remove an action and add in another, thus producing an entity that acts completely differently, with just some simple change.
Now this isn't a learning AI, it just helps organize and find the best actions to perform for a certain situation. Judging the outcome of those situations will have to be handled by some other AI system. But it in turn can affect the costs of actions if they were successful.
I've only given you a rough overview of how it works. There is plenty more reading on GOAP if you would like to implement it for your game. So have a look, and thanks for reading!
Web.media.mit.edu
Web.media.mit.edu



How big is the cost of searching the tree above for the cheapest branch? I can imagine that at a later stage where the game is more complex, the scanning of the tree itself impacts the cost of the action chosen. Is it possible to cut off some branches when using GOAP, and if yes, what determines what is cut off?
Other than that, very informative. I like tech features like these and especially the AI ones. Thank you for sharing - tracking.
This comment is currently awaiting admin approval, join now to view.